AI Development

- AI Services
-

-
 Generative AI
Generative AI -
 Data Engineering
Data Engineering -
 ML Development
ML Development -
 AI Consulting Services
AI Consulting Services -
 Chatbot Development
Chatbot Development -
 Computer Vision
Computer Vision -
 Enterprise AI Development
Enterprise AI Development -
 AI Agent Development
AI Agent Development -
 LLM Development
LLM Development -
 NLP Services
NLP Services -
 RAG as a Service
RAG as a Service -
 AI Integration Services
AI Integration Services -
 AI Automation Agency
AI Automation Agency -
 Deep Learning Development
Deep Learning Development -
 AI Voice Agent Development
AI Voice Agent Development -
 LLM Fine-Tuning
LLM Fine-Tuning -
 Enterprise AI Chatbot
Enterprise AI Chatbot -
 Vibe Coding Agency
Vibe Coding Agency -
 Business Intelligence Services
Business Intelligence Services -
 AI Workflow Automation
AI Workflow Automation -
 AI Visual Inspection Development
AI Visual Inspection Development -
 Generative AI Consulting
Generative AI Consulting -
 AI PoC Development
AI PoC Development -
 AI MVP Development
AI MVP Development -
 Mobile App Development
Mobile App Development -
 SaaS App Development
SaaS App Development -
 E-commerce Development
E-commerce Development -
 Web Development
Web Development -
 Software Development
Software Development
AI Services
AI-Powered Engineering Services
-
- Industries
-
 AI Solutions for FintechMerging AI technologies with
AI Solutions for FintechMerging AI technologies with
finance and financial services -
 AI Solutions for LogisticsWe build AI solutions for
AI Solutions for LogisticsWe build AI solutions for
Logistics service providers -
 Healthcare AI SolutionsWe build AI-powered
Healthcare AI SolutionsWe build AI-powered
healthcare solutions. -
 Retail AI SolutionsGet robust retail AI solutions built
Retail AI SolutionsGet robust retail AI solutions built
with the latest smart retail features. -
 AI Solutions for EcommerceWe build AI-powered solutions
AI Solutions for EcommerceWe build AI-powered solutions
for Ecommerce Businesses. -
 AutomotiveGet apps built to track everything
AutomotiveGet apps built to track everything
from car service to fuel economy -
 AI solutions for travelBuild AI- powered travel app
AI solutions for travelBuild AI- powered travel app
with all travel essential features -
 AI Solutions for EducationBuild an AI-powered EdTech app
AI Solutions for EducationBuild an AI-powered EdTech app
that's fun, instructive, and insightful. -
 Real Estate AI SolutionsGet AI solutions for real estate
Real Estate AI SolutionsGet AI solutions for real estate
business built with the latest features. - Hire AI Developers
-
 AI Developers
AI Developers -
 Gen AI Engineers
Gen AI Engineers -
 Data Engineers
Data Engineers -
 ML Engineers
ML Engineers -
 Vibe Coding Experts
Vibe Coding Experts -
 Python Developers
Python Developers -
 Hire Data Scientists
Hire Data Scientists -
 Prompt Engineers
Prompt Engineers
Artificial Intelligence (AI) Engineers
-
- Case Studies
- Resources
- Company
-
-
-
















Table of Contents
AI Model Testing in 2026: The Complete Guide

Key Takeaways
- AI model testing ensures models are accurate, fair, and robust enough to handle real-world data, edge cases, and scale.
- Testing uncovers issues such as bias, inconsistency, and overfitting before models create risks in production.
- Different AI model types need tailored testing approaches, from NLP explainability to generative output quality and safety.
- Continuous testing, drift detection, and CI/CD automation help maintain reliable model performance as data evolves.
Artificial Intelligence isn’t just a buzzword, it’s a backbone of modern decision-making. From healthcare diagnostics to fraud detection, AI models now shape choices that affect lives, businesses, and economies. But here’s the catch: even the most advanced model can fail spectacularly if it isn’t tested right.
Testing AI models isn’t about checking boxes. It’s about ensuring your model behaves responsibly, performs reliably, and adapts when the world changes. It’s no surprise that more than 77% of quality assurance teams are adopting AI-first quality engineering practices as part of modern testing approaches in 2026, reflecting how critical rigorous testing has become. An untested model can misclassify diseases, approve risky loans, or reinforce bias, turning innovation into liability.
That’s why AI model testing has become the silent superpower behind trustworthy AI. It bridges the gap between experimentation and real-world deployment. The goal is to build AI models that don’t just perform well in a lab but stand strong in unpredictable, messy environments.
In this guide, we’ll walk through about key things to know before testing, types of AI models and their needs and step by step guide on how to test AI models the right way. Lets start with understanding what is AI model testing. 
Table of Contents
What Is AI Model Testing?
AI model testing is the process of evaluating how well an artificial intelligence model performs, behaves, and adapts in real-world conditions. It’s not just about whether a model gives the “right” output. It’s about making sure that output is accurate, fair, robust, and reliable across different scenarios, inputs, and data shifts.
Unlike traditional software testing, where rules are defined by developers, AI models learn patterns from data. This makes their behavior harder to predict and even harder to control. That’s where testing steps in.
AI model testing helps you answer critical questions like:
- Does the model make consistent predictions across different data inputs?
- Can it handle edge cases or noisy data?
- Is it biased toward certain groups or demographics?
- Will it continue to perform well over time as data evolves?
- Does it integrate properly with the larger application or system?
Without proper testing, a model that performs great in development could completely collapse in production, leading to bad decisions, regulatory issues, or loss of user trust.
Why Testing AI Models Is Crucial
AI models aren’t just algorithms; they’re decision-makers. Whether diagnosing diseases, detecting fraud, or recommending content, their decisions influence real people and real outcomes. That’s why testing AI models isn’t optional. It’s essential.
Skipping or rushing testing can lead to serious consequences. Inaccurate predictions, biased outputs, and unexpected failures can cause financial loss, reputational harm, or even safety risks. Rigorous testing ensures that your model performs reliably before it ever reaches users.
Let’s explore why model testing is vital for every AI-driven system.
1. Accuracy Is Non-Negotiable
A model that doesn’t deliver accurate predictions is ineffective, no matter how sophisticated it seems. Inaccurate outputs can lead to:
- Misdiagnosed patients in healthcare
- Wrong financial risk assessments
- Poor product recommendations that reduce user trust
Testing validates how well your model performs on real-world, unseen data. It helps measure metrics like precision, recall, and F1 score, ensuring predictions are dependable, not lucky guesses.
2. Bias Can Break Trust
AI models learn from data, and if that data carries bias, the model will reflect it. Biased AI systems can produce unfair or even discriminatory outcomes, such as:
- Unequal hiring recommendations
- Skewed credit scoring
- Inaccurate facial recognition for specific groups
Testing exposes bias before deployment, helping teams correct unfair patterns and promote responsible AI.
3. Real-World Performance Matters
A model that performs well in testing but fails in production can cause more harm than good. True testing checks how models behave under unpredictable, large-scale, or noisy conditions.
Performance testing ensures your model can handle:
- High data loads
- Noisy or incomplete inputs
- Edge cases that challenge stability
4. Compliance Is a Legal Imperative
In regulated sectors like healthcare, banking, and insurance, testing is not just a quality step. It’s a legal requirement. Models must prove they are fair, explainable, and auditable.
Non-compliance can result in fines, lawsuits, or damaged brand reputation.
5. Consistency Builds Confidence
Trust grows through consistent results. A single wrong prediction can make users doubt an entire system. Testing ensures that your AI behaves predictably and reliably across time, data changes, and environments.
Key Things to Look For When Testing AI Models
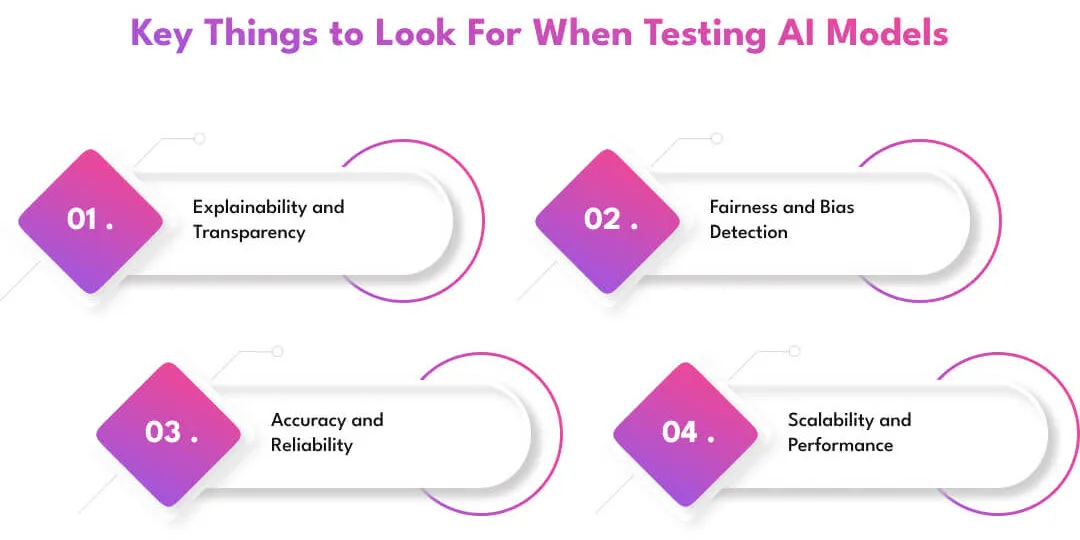
Testing an AI model isn’t just about checking if it works. It’s about making sure it works right, fairly, and consistently across real-world data, unpredictable inputs, and future scenarios.
These are the key areas to focus on when testing any AI system. Together, they help you build models that are accurate, ethical, and production-ready.
1. Explainability and Transparency
AI should not be a black box, especially when it’s making decisions that affect people’s lives. Explainability is about understanding how your model reaches its conclusions.
This builds trust with users, satisfies legal requirements, and helps identify when something has gone wrong. Tools like SHAP and LIME make it easier to interpret complex models by showing which features influenced each decision.
2. Fairness and Bias Detection
AI models can reflect or even amplify bias hidden in the data. This can lead to unfair treatment of specific groups, such as favoring one demographic over another in hiring, lending, or content recommendations.
Testing for fairness helps ensure that your model treats all users equitably. Techniques like fairness audits and disparate impact analysis are useful for uncovering hidden patterns of bias.
3. Accuracy and Reliability
At the core of every AI model is its ability to give the right answers. Accuracy tells you how often the model gets it right. Reliability checks how consistently it performs across different inputs and conditions.
You’ll often use metrics like:
- Precision (how many predicted positives were correct)
- Recall (how many actual positives were caught)
- F1 Score (a balance between precision and recall)
These scores give you a full picture of how well your model performs—not just in ideal cases, but across the board.
4. Scalability and Performance
Your model might perform well on a small test set. But what happens when it has to handle millions of inputs a day?
Scalability testing ensures that your model can:
- Process large volumes of data quickly
- Maintain accuracy under pressure
- Integrate smoothly with existing systems
This is especially important for real-time applications like fraud detection or voice assistants.
Understanding AI Model Types and Their Testing Requirements
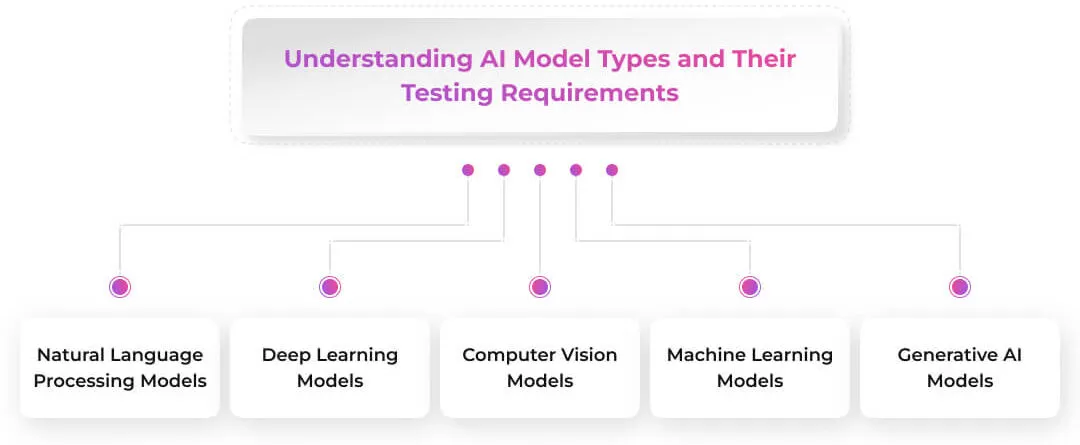
Not all AI models are built the same, and neither are their testing requirements. Each type of model learns differently, solves different problems, and faces unique challenges during development and deployment.
To test them effectively, you need to understand what each model is designed to do and what could possibly go wrong. This section breaks down the main types of AI models and the specific testing strategies they require.
Natural Language Processing (NLP) Models
NLP models help machines understand human language. Their testing needs are focused on how well they interpret, generate, and respond to text.
- Language Understanding
Can the model grasp meaning, intent, and structure in text? - Contextual Relevance
Does the model maintain context in conversations or tasks like summarization and translation? - Sentiment Detection
Is the model correctly identifying emotions, tone, or opinions in text data?
Deep Learning Models
Deep learning models are designed to handle large, complex datasets. These include:
- Convolutional Neural Networks (CNNs) used in image-related tasks
- Recurrent Neural Networks (RNNs) used in sequence and time-series data
Testing deep learning models often focuses on:
- Generalization
Can the model perform well on new, unseen data? - Overfitting
Has the model memorized training data instead of learning meaningful patterns? - Efficiency
How well does the model use system resources during training and inference?
Computer Vision Models
These computer vision models help machines interpret visual data. They are tested for:
- Image Recognition Accuracy
Does the model correctly identify objects in an image? - Object Detection
Can it locate and label multiple objects within a single image? - Robustness to Visual Changes
How well does the model perform when lighting, angles, or backgrounds vary?
Machine Learning Models
Machine learning is the foundation of most AI systems. It includes three main types, each with its own testing goals:
- Supervised Learning
These models learn from labeled data. Testing focuses on how accurately the model can predict outcomes based on input features. Common use cases include spam detection, loan approval, and image classification. - Unsupervised Learning
These models look for hidden patterns in data without labels. Testing involves checking how well the model groups or segments data and whether the results make sense in the real world. Examples include customer segmentation and anomaly detection. - Reinforcement Learning
This type of model learns by trial and error. It takes actions, receives feedback, and tries to maximize rewards over time. Testing checks how quickly and effectively the model learns a strategy, especially in dynamic environments like robotics or game simulations.
Generative AI Models
Generative AI models create new content, such as text, images, or audio. Popular examples include GANs and large language models like GPT.
Testing generative models includes:
- Output Quality
Are the results coherent, realistic, and usable? - Creativity
Does the model generate diverse, original content? - Ethical Safety
Is the output free from harmful, offensive, or biased content?
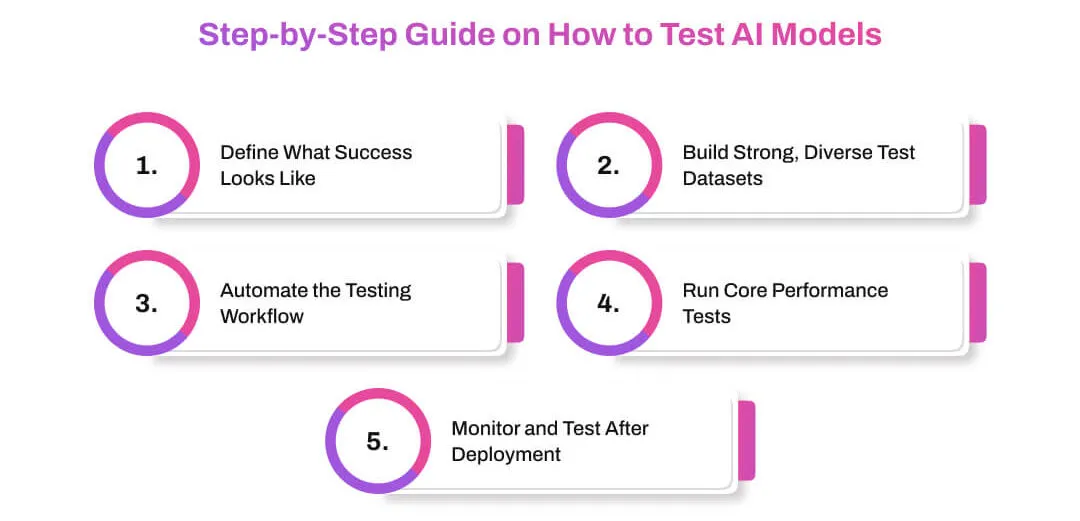
Step-by-Step Guide on How to Test AI Models
Testing an AI model isn’t a one-time task. It’s an ongoing process that begins long before deployment and continues well into real-world use. A solid testing framework ensures that your model performs accurately, fairly, and reliably—no matter how the data shifts or the system scales.
Below is a step-by-step guide to help you test AI models effectively and confidently.
Step 1: Define What Success Looks Like
Before running any tests, you need to know what a “good” model actually means for your use case. That starts with setting clear, measurable criteria for performance.
Ask questions like:
- What minimum accuracy or recall is acceptable?
- What’s the maximum false positive rate we can tolerate?
- Do different user groups receive fair treatment?
- What’s the latency limit for real-time inference?
Step 2: Build Strong, Diverse Test Datasets
No matter how clean your training data is, your model will face messier, noisier, and more complex inputs in the real world. That’s why your test dataset must reflect that diversity.
Include a mix of:
- Representative samples: Data that mirrors what the model will see in actual use.
- Edge cases: Rare or extreme inputs that can break assumptions.
- Adversarial examples: Intentionally tricky inputs to test robustness.
- Out-of-distribution data: Unseen scenarios to check generalization.
Also, use stratified sampling to ensure minority classes and sensitive user groups are well represented. This helps you detect blind spots early.
Step 3: Automate the Testing Workflow
Manual testing is slow and error-prone. Once your dataset is ready, integrate testing into your CI/CD pipeline so every model version is automatically evaluated.
Here are some tools that help automate key aspects:
- pytest (with ML-specific extensions) for unit tests
- Great Expectations for input data validation
- Deepchecks for end-to-end ML testing
- Evidently AI for model drift and data quality monitoring
Automated testing not only saves time but also ensures that testing happens consistently with every update.
Step 4: Run Core Performance Tests
Once your testing pipeline is in place and your datasets are ready, it’s time to measure how well your model performs. This step is about digging into the details and answering a key question:
Can your model deliver reliable results in real-world conditions?
Start with cross-validation. This helps ensure that your model’s performance isn’t based on luck or a specific data split. Techniques like k-fold cross-validation divide the data into segments, rotate the test sets, and average the results. This gives a more stable and trustworthy performance estimate.
Next, evaluate your model with multiple performance metrics. Accuracy alone can be misleading, especially if you’re working with imbalanced datasets. Depending on your use case, you might need to consider:
- Precision: How often the model’s positive predictions are correct
- Recall: How many actual positives the model captures
- F1 Score: The balance between precision and recall
- AUC-ROC: The model’s ability to distinguish between classes
- Confusion Matrix: A detailed view of errors and correct predictions
Using a combination of metrics helps you understand not just how accurate your model is, but how it behaves in edge cases and critical scenarios.
Step 5: Monitor and Test After Deployment
Testing doesn’t stop once the model goes live. In fact, the real test begins after deployment. Data in the real world is messy, unpredictable, and always changing. Without monitoring, a high-performing model can silently drift and fail.
Here are three essentials to include in your post-deployment testing strategy:
- Drift Detection
Over time, the data your model sees in production may no longer match the data it was trained on. This shift is called data drift. Tools like Evidently AI, WhyLabs, or Deepchecks can automatically flag changes in data distributions so you can act before performance drops. - Performance Monitoring and Alerts
Set clear thresholds for key metrics like precision, recall, or F1 score. If the model’s performance falls below these limits, alerts should trigger immediately. This helps you avoid failures that go unnoticed until they affect users or business outcomes. - Shadow Mode Testing
When you’re ready to release a new model version, test it in shadow mode. Run it on live traffic in parallel with the current model, but keep its output hidden from users. This lets you compare performance in real-world conditions without taking risks.
Post-deployment testing gives you a safety net. It keeps your model healthy, reliable, and responsive to the world it operates in.
Best Practices for Testing AI Models

Testing AI models isn’t just a technical step. It’s a discipline that ensures your model behaves as expected, adapts over time, and earns the trust of users and stakeholders. When done right, testing becomes the foundation of safe, scalable, and ethical AI.
Here are the best practices that top-performing teams follow when testing AI models.
1. Start with a Full-Lifecycle Testing Plan
Testing shouldn’t be squeezed in at the end. It needs to be part of the model’s journey from the very beginning.
Build a plan that covers every phase, including:
- Data collection and preprocessing
- Model training and validation
- Pre-deployment checks
- Live environment monitoring
This strategy should include clear goals, testing methods, and success metrics. Think beyond accuracy. Include fairness, robustness, interpretability, and performance under pressure.
A full-lifecycle approach helps you spot issues early and track how the model evolves over time.
2. Break the Silos: Combine Data Science with QA
AI testing works best when data scientists and QA engineers collaborate closely. Each brings a different strength to the table.
Data scientists understand model behavior, training data, and performance tuning. QA engineers bring skills in software testing, system integration, and edge case validation.
When these two roles work together, you get stronger test coverage, faster debugging, and fewer surprises in production.
Collaboration also helps make the model more aligned with business goals and user needs—not just technical performance.
3. Use CI/CD to Automate and Scale Testing
AI models evolve fast. New data, new features, and new versions demand constant testing. Manual checks won’t keep up.
That’s why CI/CD pipelines are essential for modern AI development. They automatically:
- Validate data quality
- Test model performance
- Detect drift or anomalies
- Deploy stable versions across environments
This creates a feedback loop where issues are caught early, fixes are faster, and models stay production-ready at all times.
CI/CD doesn’t just make testing easier. It makes your entire AI system more resilient.
4. Test in the Cloud for Real-World Scale
AI models often need massive computing power and diverse data inputs. Local environments can’t always handle that.
Cloud platforms offer scalable testing environments that adapt to your needs. You can:
- Run large-scale simulations
- Test across different geographies and devices
- Handle peak loads without lag or failures
Cloud testing is flexible, cost-efficient, and closer to the scale your model will face in production. It also helps you test under realistic latency and network conditions, which can reveal issues that local tests miss.
5. Think Long-Term: Monitor, Update, and Improve
The best testing practice isn’t a one-time event. It’s a mindset. Models that perform well today might struggle tomorrow. That’s why continuous testing and monitoring are non-negotiable.
Set up alerts for key performance metrics. Track model drift. Gather user feedback. And retrain when needed.
This ensures your AI adapts to changes in data, behavior, and the world around it—without breaking the system or user trust.
What Is the Future of AI Model Testing?
As AI systems grow more complex, testing methods must evolve to keep pace. Traditional testing won’t be enough for large language models, generative AI, or real-time decision engines. The future of AI model testing will be smarter, faster, and more automated.
We’ll see greater use of:
- AI to test AI using self-diagnosing systems
- Real-time monitoring that adapts to new data instantly
- Explainability-first tools to meet growing regulatory demands
- Ethical testing frameworks that check for bias and safety at scale
Also Read: LLM vs LAM: What’s the Real Difference and When to Use Each
Let’s Make Your AI Model Work in the Real World
AI model testing isn’t a one-time task. It’s your safety net against unexpected failures when your system goes live. Many high-performing models work in controlled environments but break down when exposed to real-world data. That’s where expert support becomes essential.
As a trusted AI development and testing service provider, Prismetric helps you bridge the gap between model development and real-world performance. Our certified professionals have solved it all—from messy data pipelines to post-deployment monitoring issues.
We handle the complexity so your models deliver results that are accurate, fair, and consistent in real use. If you’re ready to take your AI from promising to production-ready, book a consultation call today. Let’s troubleshoot the risks before they become real problems.

Conclusion
Testing is more than a stage in AI development. It is the foundation that makes artificial intelligence reliable, safe, and effective. From defining success criteria to continuous monitoring, every testing step strengthens the model’s accuracy, fairness, and performance.
As AI continues to influence how we work, think, and live, the need for thorough testing will only grow. By adopting structured and consistent testing practices, you can create AI systems that perform with confidence and earn lasting trust from users.
Vijay Chauhan is a pro vibe coder with a passion for AI development and innovation. With deep expertise in crafting smart tools, he knows how to make AI dance to the rhythm of natural language. Always eager to share knowledge, Vijay blends tech mastery with creativity to build next-gen AI experiences.
Our Recent Blog
Know what’s new in Technology and Development



14+Years’ Experience in IT
Prismetric Success Stories
0+
Happy Clients
0+
Solutions Developed
0+
Countries
0+
Developers