AI Development

- AI Services
-

-
 Generative AI
Generative AI -
 Data Engineering
Data Engineering -
 ML Development
ML Development -
 AI Consulting Services
AI Consulting Services -
 Chatbot Development
Chatbot Development -
 Computer Vision
Computer Vision -
 Enterprise AI Development
Enterprise AI Development -
 AI Agent Development
AI Agent Development -
 LLM Development
LLM Development -
 NLP Services
NLP Services -
 RAG as a Service
RAG as a Service -
 AI Integration Services
AI Integration Services -
 AI Automation Agency
AI Automation Agency -
 Deep Learning Development
Deep Learning Development -
 AI Voice Agent Development
AI Voice Agent Development -
 LLM Fine-Tuning
LLM Fine-Tuning -
 Enterprise AI Chatbot
Enterprise AI Chatbot -
 Vibe Coding Agency
Vibe Coding Agency -
 Business Intelligence Services
Business Intelligence Services -
 AI Workflow Automation
AI Workflow Automation -
 AI Visual Inspection Development
AI Visual Inspection Development -
 Generative AI Consulting
Generative AI Consulting -
 AI PoC Development
AI PoC Development -
 AI MVP Development
AI MVP Development -
 Mobile App Development
Mobile App Development -
 SaaS App Development
SaaS App Development -
 E-commerce Development
E-commerce Development -
 Web Development
Web Development -
 Software Development
Software Development
AI Services
AI-Powered Engineering Services
-
- Industries
-
 AI Solutions for FintechMerging AI technologies with
AI Solutions for FintechMerging AI technologies with
finance and financial services -
 AI Solutions for LogisticsWe build AI solutions for
AI Solutions for LogisticsWe build AI solutions for
Logistics service providers -
 Healthcare AI SolutionsWe build AI-powered
Healthcare AI SolutionsWe build AI-powered
healthcare solutions. -
 Retail AI SolutionsGet robust retail AI solutions built
Retail AI SolutionsGet robust retail AI solutions built
with the latest smart retail features. -
 AI Solutions for EcommerceWe build AI-powered solutions
AI Solutions for EcommerceWe build AI-powered solutions
for Ecommerce Businesses. -
 AutomotiveGet apps built to track everything
AutomotiveGet apps built to track everything
from car service to fuel economy -
 AI solutions for travelBuild AI- powered travel app
AI solutions for travelBuild AI- powered travel app
with all travel essential features -
 AI Solutions for EducationBuild an AI-powered EdTech app
AI Solutions for EducationBuild an AI-powered EdTech app
that's fun, instructive, and insightful. -
 Real Estate AI SolutionsGet AI solutions for real estate
Real Estate AI SolutionsGet AI solutions for real estate
business built with the latest features. - Hire AI Developers
-
 AI Developers
AI Developers -
 Gen AI Engineers
Gen AI Engineers -
 Data Engineers
Data Engineers -
 ML Engineers
ML Engineers -
 Vibe Coding Experts
Vibe Coding Experts -
 Python Developers
Python Developers -
 Hire Data Scientists
Hire Data Scientists -
 Prompt Engineers
Prompt Engineers
Artificial Intelligence (AI) Engineers
-
- Case Studies
- Resources
- Company
-
-
-
















Table of Contents
Python for Data Engineering: Everything You Need to Know

Every digital interaction today whether it’s streaming a movie, ordering food, or checking your fitness app generates data, and behind that data lies the work of data engineers, the professionals who build, maintain, and optimize the systems that process this information.
Data engineering is now more critical than ever. It powers real-time analytics, machine learning models, and business intelligence tools. As more businesses rely on data to make decisions, the demand for efficient and scalable data pipelines continues to grow. According to Verified Market Research, the global Big Data and Data Engineering Services Market is projected to reach $144.12 billion by 2030, growing at a compound annual growth rate (CAGR) of 17.60% from 2023 to 2030.
In this evolving landscape, Python has emerged as a must-have tool for data engineers. It is powerful, flexible, and widely supported. Whether it’s building ETL pipelines, automating workflows, or working with big data frameworks like Apache Spark, Python handles it all with ease.
It’s also the most used programming language globally, as per a Statista survey from 2023 Source. This popularity reflects not just Python’s versatility, but also its strong ecosystem and ease of learning.
Python’s role in data engineering isn’t just relevant but it’s essential. In the sections ahead, we’ll break down why it holds this position and how it empowers modern data workflows.
Table of Contents
Why Python is Ideal for Data Engineering
Python stands out as a favorite among data engineers because it’s simple to use, packed with powerful tools, and flexible enough to handle everything from small scripts to large-scale data systems.
Simplicity and Readability of Python
One of the best things about Python is how clean and easy it is to read. It feels more like writing in plain English than coding, which helps even beginners pick it up quickly and make sense of what’s going on.
For data engineers, being able to write and read code easily really speeds things up. Data pipelines can get complicated, but Python keeps things clear and manageable. It’s easier to spot mistakes, make updates, and share work with teammates without getting stuck in long documentation or back-and-forth code reviews.
This simplicity also lowers the learning curve. Data engineers, software developers, and even non-technical users can pick up Python and contribute to data projects. In a fast-paced environment where collaboration is key, that makes a big difference.
Strong Ecosystem with Data Libraries
What really makes Python handy for data engineers is the range of libraries it offers. You don’t have to build everything from scratch there’s usually a ready-to-use tool for whatever step you’re working on, whether it’s pulling data in, cleaning it up, or moving it where it needs to go.
If you’re working with data, chances are you’ll use libraries like Pandas to sort, filter, and clean things up it makes those tasks way simpler. For heavy number crunching, NumPy does the job when it comes to databases or big data tools, libraries like SQLAlchemy and PySpark step in and if you need to schedule tasks or manage data workflows, tools like Airflow or Luigi can save you a lot of time and hassle.
These libraries are not just functional but they’re well-documented and actively maintained. That means fewer roadblocks during development. Whether you’re working with small datasets or streaming data in real time, Python has a tool ready to support your workflow.
Scalability and Community Support
Python scales with your needs. It works just as well for a simple script as it does for handling millions of data records across distributed systems.
Just as important is the Python community. It’s one of the largest in the world, filled with developers, engineers, and data experts. This means constant improvements, updated libraries, and endless resources like tutorials, forums, and GitHub projects.
When challenges arise, solutions are often just a search away. For data engineers, that level of support translates to faster problem-solving and continuous growth.
Popular Python Libraries for Data Engineering

Ask any data engineer why they use Python, and they’ll probably mention the libraries. These tools make tough jobs feel a lot easier, whether you’re cleaning data or running complex workflows.
Pandas
Pandas is a go-to for working with tables and structured data. You can sort, filter, clean, and group your data without writing a lot of code. It’s great when you want to understand what your data looks like or get it ready for the next step.
NumPy
NumPy helps when you’re working with numbers lots of them. It’s built for speed and handles arrays way better than regular Python lists. It’s also the backbone for other tools like Pandas and works well when you need to crunch big volumes of data.
SQLAlchemy
If you’re tired of writing raw SQL every time, SQLAlchemy is a lifesaver. It lets you talk to your database using Python code. It’s flexible, works with different databases, and helps you build clean, organized queries without starting from scratch.
PySpark
When you’re dealing with massive datasets, PySpark comes in. It lets you use Apache Spark’s power with Python. Whether you’re doing batch jobs or machine learning on big data, PySpark helps you scale without switching to another language.
Airflow
With Airflow, you don’t have to keep track of data tasks manually. You just set up what needs to happen and when, and it takes care of the rest. It’s all done in Python, so making changes later on feels just like tweaking any regular script, not some complicated setup.
Dask
Sometimes your data gets too big to handle on one machine, and that’s where Dask comes in. It lets you break up the work and spread it across your system without changing how you already work with data. If you’ve used Pandas before, getting started with Dask feels pretty natural.
Requests and BeautifulSoup
Ever needed to pull data from a website? With Python, it’s pretty simple. You can use requests to get the webpage and BeautifulSoup to sift through the content and pick out exactly what you need. It’s a handy combo, even when the site structure isn’t all that clean.
Python for Data Engineering Use Cases
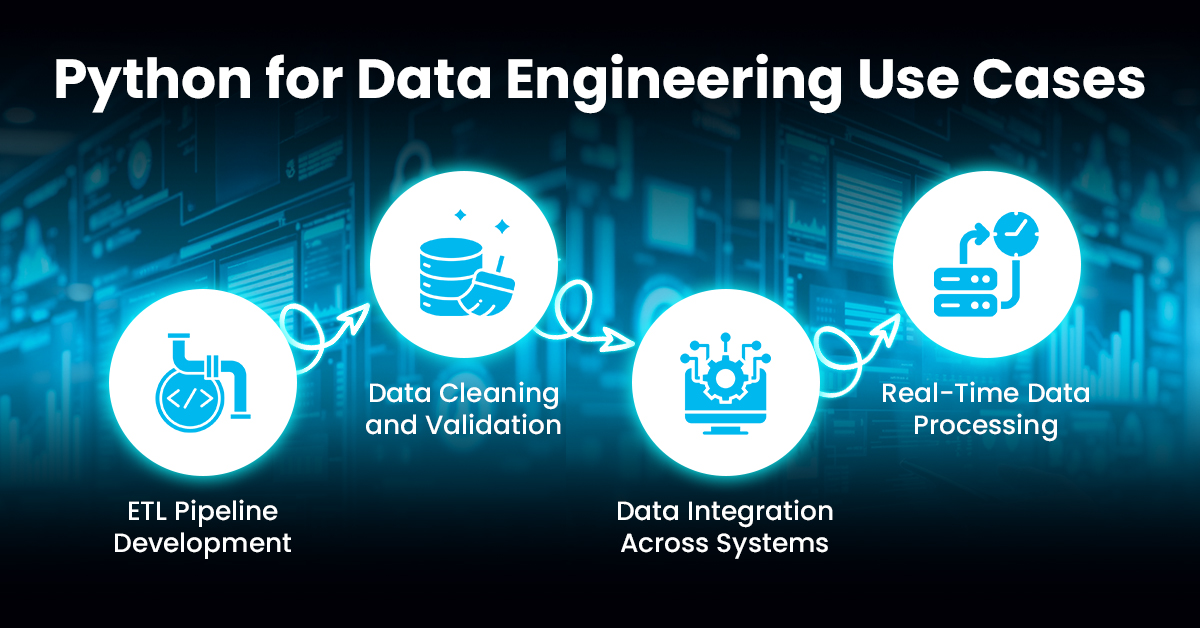
Python fits into almost every stage of the data engineering workflow. From automating routine jobs to powering real-time systems, it’s used in a wide range of practical scenarios.
ETL Pipeline Development
Python is a solid choice for building ETL (Extract, Transform, Load) pipelines. These pipelines move raw data from different sources into a usable format.
With Python, you can:
- Pull data from APIs, databases, or flat files using tools like requests or SQLAlchemy
- Clean and shape that data using Pandas or custom scripts
- Load processed data into data warehouses using connectors like psycopg2 or cloud SDKs
It also works well with scheduling tools like Apache Airflow or Luigi, so you can automate the whole ETL flow. Whether it’s a daily job or a batch running every few minutes, Python keeps it smooth and manageable because it’s easy to read and maintain, making changes to workflows is less of a hassle.
Data Cleaning and Validation
Dirty or inconsistent data can throw off your entire analytics or machine learning project. Python makes the cleaning process quicker and more reliable.
You can:
- Detect missing values or outliers using Pandas and NumPy
- Apply business rules to validate entries
- Use libraries like Cerberus or Pydantic for schema validation
What makes Python stand out is how easy it is to write logic that’s both clear and maintainable. You don’t need complex tools or clunky workarounds to get the job done when your data is clean and accurate, your analysis is more reliable and your machine learning models work better.
Data Integration Across Systems
Data often lives in different places—cloud storage, SQL databases, third-party APIs, spreadsheets. Python helps tie all that together.
It supports:
- API connections with requests or httpx
- Reading and writing to databases with SQLAlchemy or PyMySQL
- Accessing cloud services through SDKs like boto3 (AWS) or google-cloud
You can build scripts that bring data from one place, transform it, and send it somewhere else, all in one flow. This kind of integration is key when building central data platforms or syncing systems across a business.
Real-Time Data Processing
Real-time data is everywhere now, from app notifications to sensor streams. Python plays a big role in handling these fast-moving data flows.
You can use:
- Kafka-Python or Faust for consuming and processing live streams
- AsyncIO for building lightweight, event-driven services
- Frameworks like Spark Streaming through PySpark for scalable processing
These tools let you react to events as they happen whether that’s flagging a fraud alert, updating a dashboard, or triggering downstream actions. Python makes it easier to build and manage these real-time systems without getting stuck in low-level code.
Challenges of Using Python for Data Engineering
Python makes a lot of data tasks easier, but it’s not without its challenges. Once you start building bigger projects, a few common issues tend to show up.
Performance Limitations
Python isn’t the fastest language out there. When you’re processing huge datasets or running heavy computations, it can slow things down. For quick tasks, it’s great. But for high-performance needs, you might need to bring in tools like Spark or shift some work to compiled languages like C++.
Dependency Management
As your projects grow, managing packages can get tricky. Conflicts between libraries or outdated versions can break things unexpectedly. Tools like pip, venv, and Poetry help, but keeping everything in sync still takes extra care—especially across different environments.
Scaling Scripts for Production Use
What works well in a local test script doesn’t always translate to production. Scaling Python jobs to run reliably in cloud or distributed environments can be a challenge. You often need to refactor code, handle failures better, and set up logging or monitoring tools to keep things running smoothly.
Conclusion
Python has become a key part of modern data engineering for good reason. It’s easy to learn, flexible to use, and supported by a wide range of powerful libraries. Whether you’re building ETL pipelines, cleaning messy datasets, or managing real-time workflows, Python gives you the tools to do it efficiently.
Of course, it has challenges like performance limits and scaling but the benefits often outweigh the trade-offs. And with the right approach, those hurdles can be managed.
If you’re planning to build strong data solutions or expand your team, it’s worth looking into skilled Python experts. You can hire Python developers who understand both the language and the demands of real-world data projects.
In the world of data, Python isn’t just useful it’s essential.
As the tech-savvy Project Manager at Prismetric, his admiration for app technology is boundless though!He writes widely researched articles about the AI development, app development methodologies, codes, technical project management skills, app trends, and technical events. Inventive mobile applications and Android app trends that inspire the maximum app users magnetize him deeply to offer his readers some remarkable articles.
Our Recent Blog
Know what’s new in Technology and Development


14+Years’ Experience in IT
Prismetric Success Stories
0+
Happy Clients
0+
Solutions Developed
0+
Countries
0+
Developers