AI Development

- AI Services
-

-
 Generative AI
Generative AI -
 Data Engineering
Data Engineering -
 ML Development
ML Development -
 AI Consulting Services
AI Consulting Services -
 Chatbot Development
Chatbot Development -
 Computer Vision
Computer Vision -
 Enterprise AI Development
Enterprise AI Development -
 AI Agent Development
AI Agent Development -
 LLM Development
LLM Development -
 NLP Services
NLP Services -
 RAG as a Service
RAG as a Service -
 AI Integration Services
AI Integration Services -
 AI Automation Agency
AI Automation Agency -
 Deep Learning Development
Deep Learning Development -
 AI Voice Agent Development
AI Voice Agent Development -
 LLM Fine-Tuning
LLM Fine-Tuning -
 Enterprise AI Chatbot
Enterprise AI Chatbot -
 Vibe Coding Agency
Vibe Coding Agency -
 Business Intelligence Services
Business Intelligence Services -
 AI Workflow Automation
AI Workflow Automation -
 AI Visual Inspection Development
AI Visual Inspection Development -
 Generative AI Consulting
Generative AI Consulting -
 AI PoC Development
AI PoC Development -
 AI MVP Development
AI MVP Development -
 Mobile App Development
Mobile App Development -
 SaaS App Development
SaaS App Development -
 E-commerce Development
E-commerce Development -
 Web Development
Web Development -
 Software Development
Software Development
AI Services
AI-Powered Engineering Services
-
- Industries
-
 AI Solutions for FintechMerging AI technologies with
AI Solutions for FintechMerging AI technologies with
finance and financial services -
 AI Solutions for LogisticsWe build AI solutions for
AI Solutions for LogisticsWe build AI solutions for
Logistics service providers -
 Healthcare AI SolutionsWe build AI-powered
Healthcare AI SolutionsWe build AI-powered
healthcare solutions. -
 Retail AI SolutionsGet robust retail AI solutions built
Retail AI SolutionsGet robust retail AI solutions built
with the latest smart retail features. -
 AI Solutions for EcommerceWe build AI-powered solutions
AI Solutions for EcommerceWe build AI-powered solutions
for Ecommerce Businesses. -
 AutomotiveGet apps built to track everything
AutomotiveGet apps built to track everything
from car service to fuel economy -
 AI solutions for travelBuild AI- powered travel app
AI solutions for travelBuild AI- powered travel app
with all travel essential features -
 AI Solutions for EducationBuild an AI-powered EdTech app
AI Solutions for EducationBuild an AI-powered EdTech app
that's fun, instructive, and insightful. -
 Real Estate AI SolutionsGet AI solutions for real estate
Real Estate AI SolutionsGet AI solutions for real estate
business built with the latest features. - Hire AI Developers
-
 AI Developers
AI Developers -
 Gen AI Engineers
Gen AI Engineers -
 Data Engineers
Data Engineers -
 ML Engineers
ML Engineers -
 Vibe Coding Experts
Vibe Coding Experts -
 Python Developers
Python Developers -
 Hire Data Scientists
Hire Data Scientists -
 Prompt Engineers
Prompt Engineers
Artificial Intelligence (AI) Engineers
-
- Case Studies
- Resources
- Company
-
-
-
















Table of Contents
What Are AI Models? Complete Guide

Key Takeaways
- AI models learn patterns from data, enabling them to recognize, predict, and make decisions without explicit programming.
- Every AI model depends on three core elements: high-quality data, effective algorithms, and fine-tuned parameters.
- Machine learning includes multiple learning approaches, such as supervised, unsupervised, reinforcement learning, and deep learning.
- Advanced AI models like LLMs, computer vision systems, and generative AI now power everyday applications and digital experiences.
- Training an AI model requires clear goals, clean data, proper algorithm selection, continuous testing, and ongoing tuning.
- Deployment is only the beginning; AI models must be monitored, updated, and retrained to maintain real-world accuracy.
Table of Contents
What Are AI Models?
Imagine you’re teaching a child how to recognize animals. You show pictures of cats and dogs over and over. Eventually, the child learns to tell them apart, even with new images they’ve never seen before. That’s exactly how an AI model works.
An AI model is a computer program trained to recognize patterns in data and make decisions or predictions based on those patterns. Instead of instincts, it relies on examples, lots of them. It learns by analyzing historical data, identifying relationships, and forming a “mental model” it can use in the future.

At its core, an AI model answers one big question:
“Given what I’ve seen before, what should I do with what I see now?”
Let’s break it down.
- Input: The model receives new data, like an image, a sentence, or a customer profile.
- Processing: It applies what it has learned from previous data (the training phase).
- Output: It predicts an outcome, classifies information, or takes an action.
For example:
- In natural language processing, AI models help virtual assistants understand your voice commands.
- In computer vision, they identify objects in images or video footage.
- In predictive analytics, they forecast sales trends or detect fraud before it happens.
AI models aren’t static tools. They evolve. The more data they see, and the better that data is, the smarter they get.
Think of them as digital brains. But unlike humans, they don’t tire, forget, or get distracted. When trained well, they consistently deliver insights, automate decisions, and unlock possibilities in every industry, from healthcare and finance to marketing and robotics.
The Core Components of an AI Model
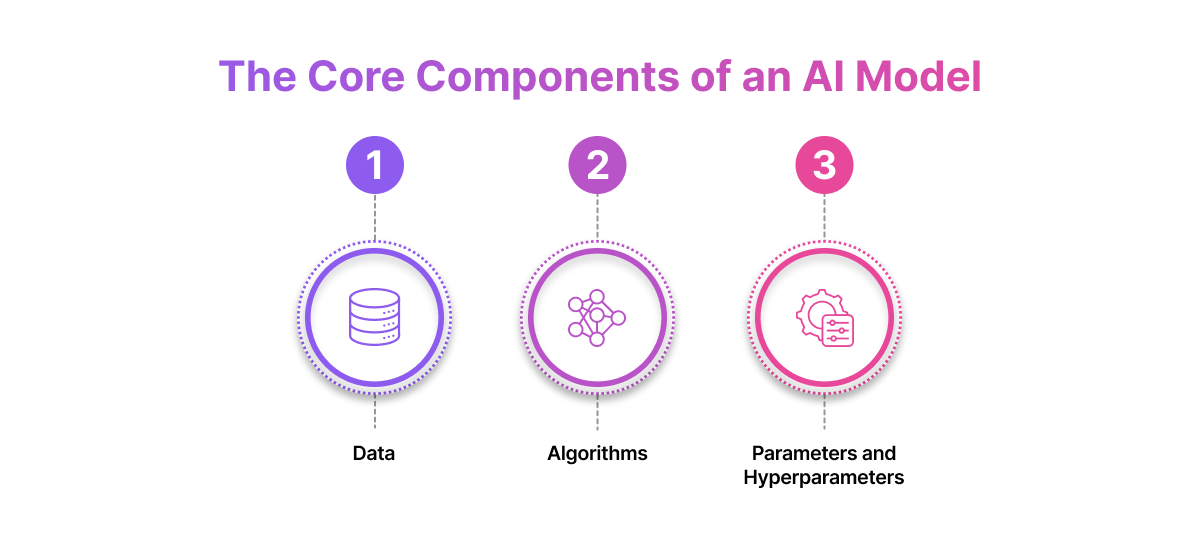
Behind every intelligent system is a set of building blocks working together like gears in a finely tuned machine. To understand how AI models function, we need to explore three core components: data, algorithms, and parameters.
Let’s break it down in plain English.
Data: The Fuel That Powers Intelligence
Without data, an AI model is like a car with no fuel. It simply won’t move.
Data is the raw material AI models use to learn. Every image labeled “cat,” every customer review, every purchase history, it all feeds the model’s brain. During training, the model looks for patterns and learns how to associate inputs with outputs.
But not all data is created equal.
- High-quality data is accurate, complete, and relevant. It helps models learn correctly.
- Poor-quality data, like outdated, biased, or messy information, can mislead the model and produce bad results.
For example, a voice assistant trained on only one accent might struggle to understand others. That’s a data problem, not a flaw in the technology.
Algorithms: The Learning Engines
If data is the fuel, algorithms are the engine. They’re the set of rules the model uses to process data, identify patterns, and learn.
Think of an algorithm as a recipe.
- It tells the AI model how to learn from data.
- Different algorithms work better for different tasks (e.g., decision trees for classification, linear regression for prediction).
The choice of algorithm shapes how the model learns. It’s like choosing a workout plan, some build strength, others build endurance.
Parameters and Hyperparameters: Fine-Tuning the Brain
Here’s where things get a little deeper, but still simple.
Once a model starts learning, it tweaks internal settings called parameters. These are the model’s “memory knobs”, values it adjusts during training to get better predictions.
For example, in a linear model, a parameter might represent the slope of a line. As the model trains, it changes this value to better fit the data.
Then there are hyperparameters, these are like settings you choose before training starts.
- How many layers in a neural network?
- How fast should the model learn?
- How many times should it look at the data?
You set these in advance, and they influence how the learning unfolds. Choosing the right hyperparameters often involves trial, error, and experimentation.
The Main Types of AI Models: From Simple to Sophisticated
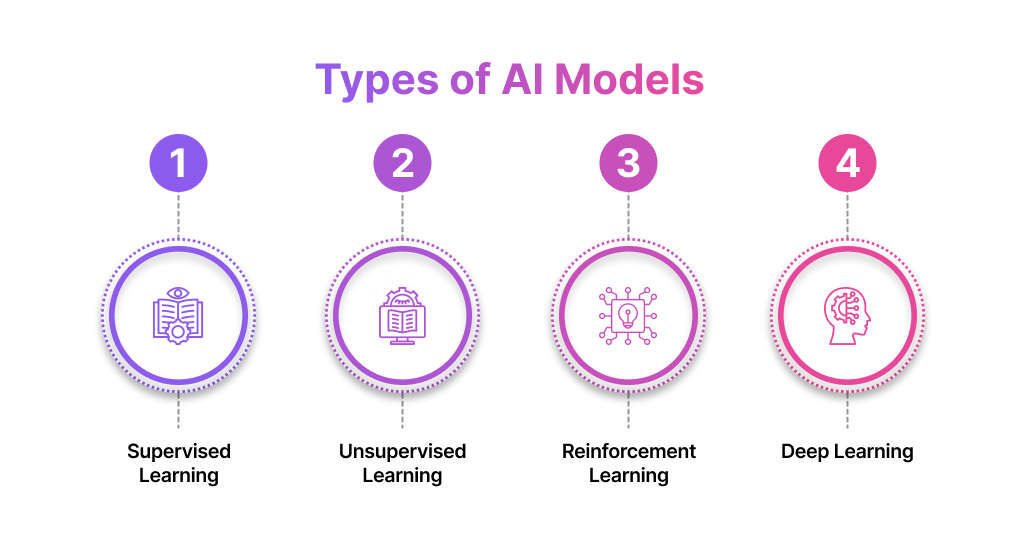
AI models vary in how they learn, adapt, and solve problems. At the heart of these models lies machine learning, a method of teaching machines to learn from data without being explicitly programmed for every task.
Machine learning models use statistical AI rather than symbolic AI. While traditional rule-based systems follow rigid “if-this-then-that” logic, machine learning (ML) models are trained using mathematical algorithms applied to sample datasets. These datasets act as learning material, enabling models to make informed predictions or decisions in real-world scenarios.
Broadly, machine learning techniques can be categorized into three primary types based on how they learn: supervised learning, unsupervised learning, and reinforcement learning. A fourth category, deep learning, builds upon these foundations to handle more complex tasks.
Supervised Learning
Also known as “classic” machine learning, supervised learning depends on labeled datasets. In this approach, a human expert pre-classifies the input data by assigning correct labels or outcomes.
For example, to train an image recognition model to distinguish between cats and dogs, a data scientist first tags a large dataset of images with labels like “cat” or “dog.” These labels, along with associated features, such as fur texture, ear shape, or size, help the model identify and learn the visual characteristics unique to each category.
As the model trains, it uses this labeled data to create rules and make predictions. Once trained, it can apply those rules to new, unseen data and classify it accurately.
Common use cases:
- Email spam detection
- Disease classification from X-rays
- Credit scoring and loan approval systems
Unsupervised Learning
Unlike supervised learning, unsupervised models don’t rely on labeled data. These models explore and analyze raw data without any predefined outcomes. Their goal is to discover hidden structures, patterns, or groupings within the data on their own.
Instead of answering a known question, unsupervised learning models ask the data what stories it holds. For instance, an e-commerce platform might use these models to identify clusters of users with similar purchasing behavior, without having to define those groups in advance.
This makes unsupervised learning especially powerful for tasks like segmentation, pattern discovery, and anomaly detection.
Common use cases:
- Customer segmentation in marketing
- Product recommendation systems
- Detecting fraudulent or unusual financial transactions
Reinforcement Learning
In reinforcement learning, the model learns by interacting with its environment. It takes actions, observes outcomes, and receives feedback in the form of rewards or penalties. Over time, through trial and error, it learns which strategies lead to the best results.
Think of it like training a dog: good behavior is rewarded, mistakes are corrected. The AI agent keeps refining its actions to maximize rewards.
Reinforcement learning is ideal for situations where decisions need to be made sequentially, and the environment responds dynamically to those choices.
Common use cases:
- Training self-driving cars to navigate traffic
- Optimizing trading strategies in finance
- Teaching AI agents to master games like chess or Go
Deep Learning
Deep learning is a specialized subset of machine learning, often considered an extension of unsupervised learning. It is designed to mimic how the human brain processes information, using structures called artificial neural networks.
These networks consist of multiple layers of interconnected nodes (neurons), where each layer refines the data further. The first layers detect simple features (like edges in images), while deeper layers capture more abstract concepts (like faces or objects).
Training a deep learning model involves two key processes:
- Forward propagation: Data flows through the layers, and each layer extracts and transforms features.
- Backpropagation: The model evaluates its errors, adjusts internal weights, and improves accuracy iteratively.
Deep learning is the technology behind many state-of-the-art AI applications, including large language models (LLMs) such as ChatGPT, image generation tools like DALL·E, and advanced speech recognition systems.
However, it requires massive amounts of data and computational power, often leveraging cloud infrastructure or specialized hardware like GPUs.
Common use cases:
- Natural language understanding in chatbots
- Facial recognition and object detection
- Autonomous vehicles and robotics
Advanced AI Models You Hear About Every Day
You’ve probably heard the buzzwords, ChatGPT, DALL·E, self-driving cars, and AI-generated art. But what powers these everyday marvels?
The answer lies in advanced AI models, most of which are built using deep learning. These models rely on complex structures called neural networks, which simulate how the human brain processes information.
Unlike traditional models that handle simple tasks, deep learning models can analyze language, understand images, and even generate new content. They often blend different learning methods, supervised, unsupervised, or reinforcement learning, depending on the task.
Let’s explore the most important types you’re interacting with almost every day.
Large Language Models (LLMs)
LLMs are deep learning models trained on massive amounts of text, websites, books, news articles, and more. They’re designed to understand and generate human-like language with surprising fluency.
They don’t “think” like humans, but they’re trained to predict the next word in a sentence based on everything they’ve seen before. This makes them incredibly good at writing, translating, summarizing, and holding conversations.
You’ve seen them in action with tools like:
- ChatGPT
- Google Bard
- Meta’s LLaMA
- Claude
Primary Uses:
- Chatbots and virtual assistants
- Automated content creation
- Language translation
- Text summarization
- Code generation
Real-World Example:
ChatGPT uses an LLM called GPT (Generative Pre-trained Transformer), trained on billions of words. When you ask it a question, it responds by generating coherent, relevant text, like a hyper-educated assistant.
Computer Vision Models
These models allow machines to “see” and interpret visual data, like photos, videos, or even real-time camera feeds. They learn to recognize patterns in pixels and classify what they observe.
Computer vision uses deep learning techniques, often Convolutional Neural Networks (CNNs), to extract features such as edges, shapes, and colors, and to understand objects or scenes.
Primary Uses:
- Facial recognition (on your phone or at airports)
- Object detection (for self-driving cars)
- Medical imaging (analyzing X-rays or MRIs)
- Quality inspection in manufacturing
- Visual search and augmented reality
Real-World Example:
A self-driving car uses computer vision to detect traffic lights, pedestrians, and other vehicles. The model helps the car make real-time driving decisions based on what it sees.
Generative AI
Generative AI refers to models that don’t just analyze data, they create something new. These models can write stories, compose music, generate code, design images, and even produce voiceovers.
They’re powered by LLMs or computer vision models and trained on huge datasets. What makes them special is their creative ability.
Primary Uses:
- Image generation from text prompts (like DALL·E 2 or Midjourney)
- Text generation (like writing articles or poems)
- Audio and music synthesis
- AI-powered design and video editing
- Code autocompletion tools (like GitHub Copilot)
Real-World Example:
You type, “a robot riding a horse in a futuristic city,” and DALL·E 2 turns that text into a photorealistic image. That’s generative AI in action.
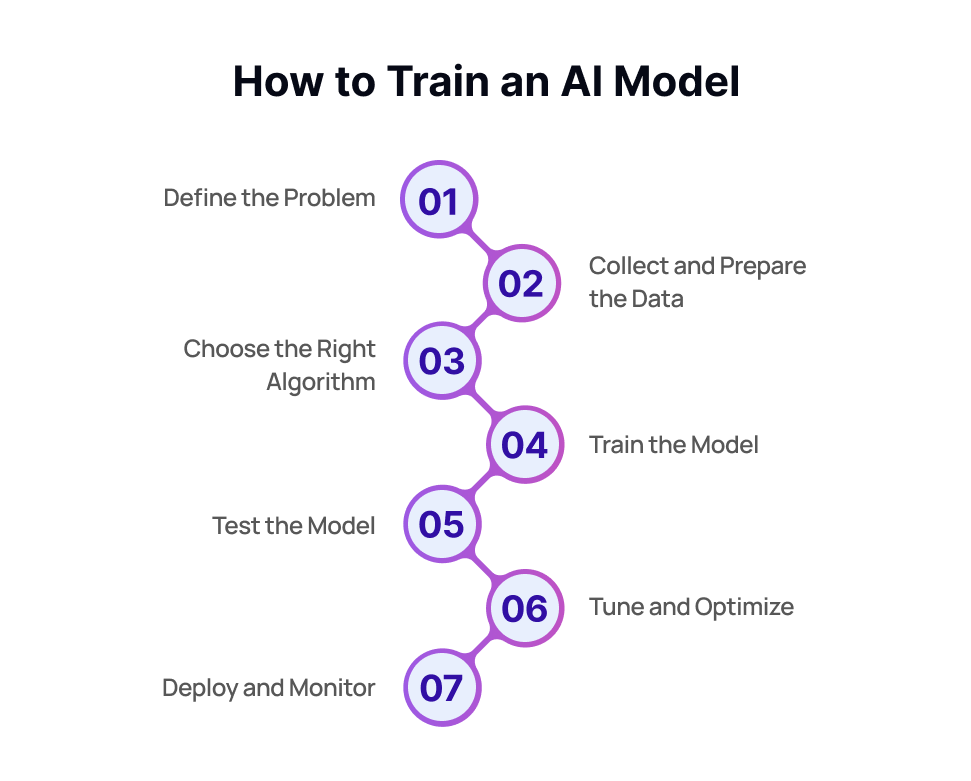
How to Train an AI Model
Training an AI model is where the magic happens. It’s the process that turns raw data into real intelligence.
Just like a student learns by studying past exams, AI models learn by analyzing historical data, spotting trends, finding patterns, and making sense of what they see. The better the training process, the more accurate and useful the model becomes.
Let’s break down how this works.
Step 1: Define the Problem
Every AI project starts with a clear question:
- Do you want to predict house prices?
- Spot fraudulent transactions?
- Recommend the next binge-worthy show?
Your objective shapes everything that follows, especially what kind of data and model you’ll need.
Step 2: Collect and Prepare the Data
Data is the foundation of all AI training. But raw data isn’t enough. It needs to be relevant, clean, and structured.
- Supervised learning needs labeled data, where the input and correct output are already known.
- Unsupervised learning works with unlabeled data to find hidden patterns.
- Reinforcement learning involves learning from rewards or penalties based on actions.
If you’re training a spam filter, you need thousands of emails marked as “spam” or “not spam.” That’s your labeled dataset.
Before training begins, the data must go through preprocessing steps like:
- Removing duplicates or errors
- Filling in missing values
- Converting data into a machine-readable format
Step 3: Choose the Right Algorithm
Now it’s time to pick your learning engine. Different problems call for different algorithms:
- Linear regression for predicting values
- Decision trees for classification
- Convolutional neural networks (CNNs) for image analysis
Your algorithm decides how the model learns from the data.
Step 4: Train the Model
Here’s where the actual learning begins. You feed your dataset into the model, and it starts adjusting its internal settings, called parameters, to improve accuracy.
The model analyzes the input data, compares its predictions to the correct answers (in supervised learning), and tweaks itself to do better next time. This process is repeated thousands, or even millions, of times.
Think of it like practicing a sport: the more reps, the better the performance.
Step 5: Test the Model
Once training is done, it’s time to see how well the model performs on new, unseen data.
- You split your original dataset into training and testing sets.
- The model is evaluated using performance metrics like accuracy, precision, recall, or F1 score, depending on the task.
If the model performs poorly, you may need to retrain it with more or better-quality data.
Step 6: Tune and Optimize
No model is perfect after the first try. You’ll often go back and:
- Adjust hyperparameters (like learning rate or batch size)
- Try different algorithms
- Add more features or clean the data further
This is called model optimization, and it’s a critical part of building an AI model that’s ready for the real world.
Step 7: Deploy and Monitor
Once your model performs well, it’s time to deploy it, whether in an app, a chatbot, or a recommendation engine.
But training doesn’t stop at deployment.
Real-world conditions change. New data emerges. That’s why AI models must be monitored and periodically retrained to stay sharp and reliable.
How to Test and Deploy AI Models
Training an AI model is just the beginning. Before using it in the real world, you need to make sure it works the way you expect. That’s where testing and deployment come in.
Testing AI Models
Testing tells you how well your AI model performs when it sees new data, data it hasn’t seen before. If the model only works on training data, it’s like a student who memorized answers but can’t solve new problems. That’s called overfitting, and we want to avoid it.
To prevent that, we use a technique called cross-validation. This means splitting your data into smaller chunks, some for training and some for testing. One popular method is k-fold cross-validation, where data is divided into “folds” and the model is trained and tested multiple times using different combinations.
Common Metrics for Testing
Different models use different measurements, depending on the task. Here are the basics:
For classification tasks (e.g., is this email spam or not?):
- Accuracy – How often the model gets it right overall.
- Precision – Of all the positive predictions, how many were correct?
- Recall – Of all the actual positives, how many did the model find?
- F1 Score – A balance between precision and recall.
- Confusion Matrix – A visual tool showing how many correct and wrong guesses the model made for each category.
For regression tasks (e.g., predicting house prices):
- Mean Absolute Error (MAE) – How far off the predictions are, on average.
- Mean Squared Error (MSE) – Like MAE, but errors are squared to highlight big mistakes.
- Root Mean Squared Error (RMSE) – The square root of MSE, giving error in the original units.
- Mean Absolute Percentage Error (MAPE) – The average error, shown as a percentage.
Simple Example:
If your model says a house will sell for $300,000 but the actual price is $310,000, the error is $10,000. These metrics help you measure such errors across all your predictions.
Deploying AI Models
Once your model passes the test, it’s ready to go live, this is called deployment. Think of it like moving a project from your laptop to the real world.
To do this, you need:
- A server or computer to run the model continuously.
- Enough processing power to handle the data and make predictions quickly.
Here’s what powers most deployed AI systems:
- CPUs – Good for simple tasks and smaller models.
- GPUs – Better for complex models, like deep learning, because they process many things at once.
Most developers use tools like TensorFlow, PyTorch, or Caffe2 to deploy models with just a few lines of code.
Deployment is often done on:
- Cloud platforms (like AWS, Google Cloud, Azure)
- On-premise servers (for private, secure environments)
- Edge devices (like smartphones or IoT devices for real-time use)
Even after deployment, models need to be monitored. If data or conditions change, they may need retraining to stay accurate.
Build AI Models with Prismetric
If you’re looking to transform your business with the power of AI, Prismetric is the partner you can trust.
As a leading AI development company, we specialize in designing, training, and deploying intelligent systems that solve real-world business problems. From building intelligent chatbots to developing advanced AI agents, we don’t just follow the latest AI trends, we set them in motion for our clients.
What Makes Prismetric Different?
Unlike generic software firms, we offer end-to-end AI development services with deep domain expertise. Our team of certified data scientists, machine learning engineers, and AI architects works hand-in-hand with you to bring smart solutions to life.
Here’s what we bring to the table:
AI Strategy & Consultation
We help you identify where AI fits into your business. Whether you need automation, personalization, or prediction, we’ll create a roadmap tailored to your goals.
Custom AI Model Development
We design models built specifically for your needs using cutting-edge technologies like:
- Natural Language Processing (NLP)
- Computer Vision
- Predictive Analytics
- Generative AI
- Reinforcement Learning
Our AI solutions span everything from fraud detection to recommendation systems, supply chain optimization, and intelligent forecasting.
AI Agent Development Services
Need smart systems that can act, learn, and adapt on their own? Our AI agent development services are ideal for creating intelligent assistants, autonomous bots, and decision-making systems that operate in real-time environments.
Scalable Infrastructure
We build AI models that are ready for scale, deployed on secure, high-performance platforms like AWS, Azure, Google Cloud, or your private servers.
Full Lifecycle Management
AI isn’t one-and-done. We provide ongoing support to monitor, retrain, and optimize your models as your data evolves, keeping performance high and costs low.
Proven Results Across Industries
Prismetric has delivered high-impact AI solutions for clients in:
- Retail: Personalized recommendations, customer segmentation, inventory forecasting
- Healthcare: Diagnostic AI tools, patient engagement systems, predictive health monitoring
- Finance: Risk modeling, fraud detection, robo-advisors
- Logistics: Route optimization, demand prediction, real-time tracking agents
Whether you’re a startup exploring AI for the first time or an enterprise modernizing your tech stack, we have the experience and tools to lead the way.

Partner with a Future-Ready AI Development Company
The future belongs to companies that leverage AI intelligently. At Prismetric, we don’t just build models, we create AI solutions that deliver measurable business value.
Stay ahead of AI trends, tap into smarter decision-making, and build intelligent agents that work 24/7.
Visit Prismetric.com to learn how our AI development company can help you build the next generation of digital solutions.
Let’s turn your data into decisions, and your vision into reality.
FAQs
1. What is an AI model and how does it work?
An AI model is a mathematical algorithm trained on large datasets to recognize patterns, make predictions, or perform tasks such as classification, recommendation, or language generation. It works by learning from data and improving over time.
2. What are the different types of AI models?
Common types of AI models include supervised learning models (e.g., decision trees, SVMs), unsupervised models (e.g., clustering algorithms), reinforcement learning models, and deep learning models like neural networks.
3. What are popular examples of AI models used today?
Popular AI models include GPT-4 (language generation), BERT (natural language understanding), ResNet (image recognition), and DALL·E (image generation), each optimized for specific AI tasks across industries.
4. How are AI models trained and deployed?
AI models are trained using large datasets and computing power to optimize their performance. Once trained, they are deployed through APIs, cloud platforms, or embedded into applications to perform real-world tasks.
5. Why are AI models important in modern technology?
AI models power technologies like chatbots, recommendation engines, voice assistants, fraud detection systems, and autonomous vehicles, making them critical for automating processes, improving efficiency, and enhancing user experiences
As the tech-savvy Project Manager at Prismetric, his admiration for app technology is boundless though!He writes widely researched articles about the AI development, app development methodologies, codes, technical project management skills, app trends, and technical events. Inventive mobile applications and Android app trends that inspire the maximum app users magnetize him deeply to offer his readers some remarkable articles.
Our Recent Blog
Know what’s new in Technology and Development



14+Years’ Experience in IT
Prismetric Success Stories
0+
Happy Clients
0+
Solutions Developed
0+
Countries
0+
Developers