Large Language Models (LLMs) are powering more than just chatbots, they’re driving document search, content generation, summarization, and even code automation.
But building with LLMs isn’t plug-and-play. You need a tech stack designed for prompt handling, vector search, model orchestration, and performance monitoring.
This guide is for developers, product teams, and tech leads looking to build LLM apps that actually scale. We’ll break down each layer of the modern LLM stack and help you make smart, future-ready choices.
Table of Contents
Two Core Strategies for LLM Application Development: RAG vs. Fine-Tuning
When building LLM applications, two primary strategies emerge: In-Context Learning with Retrieval-Augmented Generation (RAG) and Fine-Tuning. Each offers distinct advantages and challenges. Let’s delve into both to help you determine the best fit for your needs.
RAG enhances LLM outputs by integrating external knowledge sources. Instead of relying solely on pre-trained data, RAG retrieves relevant information from databases or documents in real-time, providing the model with up-to-date context before generating a response.
Pros:
Quick Implementation: No need for extensive model retraining.
Dynamic Knowledge Integration: Easily update or modify the knowledge base without altering the model.
Reduced Hallucinations: Grounding responses in real data minimizes inaccuracies.
Cons:
Complex Prompt Engineering: Crafting effective prompts to utilize retrieved data can be challenging.
Latency Issues: Real-time data retrieval may introduce delays.
Context Window Limitations: Large retrieved documents might exceed the model’s input capacity.
Ideal Use Cases:
Applications requiring current or frequently updated information.
Scenarios where retraining models is impractical or resource-intensive.
Systems needing transparency and source attribution in responses.
Fine-Tuning LLMs
How It Works:
Fine-tuning involves further training a pre-existing LLM on a specific dataset, allowing it to adapt to particular tasks or domains. This process adjusts the model’s weights to better align with the desired outputs.
Pros:
Task Specialization: Enhances model performance on specific tasks or industries.
Improved Efficiency: Tailored models can process inputs faster for designated tasks.
Consistent Outputs: Reduces variability in responses for standardized tasks.
Cons:
Resource Intensive: Requires significant computational power and time.
Maintenance Overhead: Updating the model necessitates additional training cycles.
Risk of Overfitting: The model might become too specialized, reducing its versatility.
Ideal Use Cases:
Applications with stable, unchanging datasets.
Tasks demanding high accuracy in a specific domain.
Environments where consistent output is paramount.
Hybrid Approaches: Combining RAG and Fine-Tuning
In many scenarios, a hybrid strategy leverages the strengths of both RAG and fine-tuning. For instance, fine-tune an LLM on domain-specific data to establish a strong foundation, then employ RAG to supplement responses with the most recent information.
Benefits:
Enhanced Accuracy: Fine-tuning ensures domain relevance, while RAG provides current context.
Flexibility: Adapt to new information without retraining the entire model.
Balanced Performance: Achieve both depth and breadth in responses.
Considerations:
Increased Complexity: Implementing both methods requires careful system design.
Resource Allocation: Balancing computational resources between training and real-time retrieval is crucial.
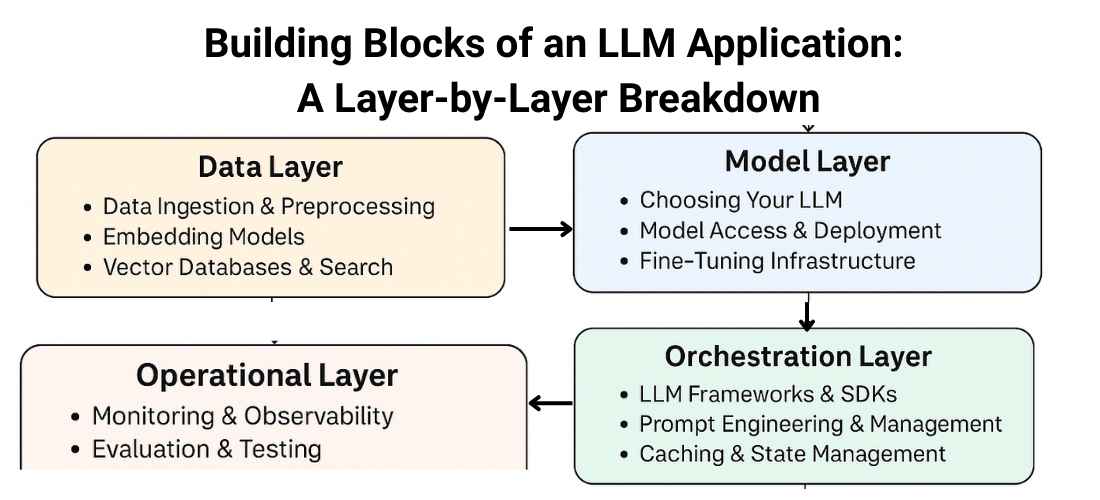
LLM Application Tech Stack: Key Layers and Components
Data Layer: The Foundation of Intelligence
The Data Layer is the bedrock of any LLM application. It encompasses the processes and tools required to collect, preprocess, and structure data, ensuring it’s in a format suitable for LLM consumption.
1. Data Ingestion & Preprocessing
Sources:
Documents: PDFs, DOCs
Webpages
Databases
APIs
Real-time data streams
Tools & Techniques:
ETL Pipelines: Tools like Apache Airflow, Dagster, and Prefect are instrumental in orchestrating data workflows. They handle tasks such as data extraction, transformation, and loading, ensuring data flows seamlessly from source to destination.
Data Connectors: Platforms like Unstructured.io and LlamaIndex offer connectors that facilitate the extraction of data from various sources, converting unstructured data into structured formats suitable for LLMs.
Data Cleaning & Formatting: Libraries like Pandas are widely used for data cleaning tasks, such as handling missing values, removing duplicates, and formatting data consistently. For larger datasets, Apache Spark provides distributed data processing capabilities, enabling efficient handling of big data.
Chunking Strategies: Breaking down large documents into smaller, manageable chunks ensures that LLMs can process and understand the content effectively, especially given their context window limitations.
2. Embedding Models
Embedding models transform textual data into numerical vectors, capturing semantic meanings and relationships between words or phrases.
Options:
OpenAI: Models like text-embedding-3-small and text-embedding-3-large offer high-performance embeddings with dimensions of 1536 and 3072, respectively.
Cohere: The Embed v3 series provides multilingual support with options like 1024 or 384-dimensional embeddings, catering to various application needs.
Open-Source Models: Hugging Face hosts a plethora of open-source embedding models, including Sentence Transformers, BGE, GTE, and E5. These models offer flexibility and can be fine-tuned for specific tasks.
Considerations:
Performance: Evaluate the model’s accuracy and speed.
Cost: Consider licensing fees and computational requirements.
Dimensionality: Higher dimensions may capture more nuances but require more storage and processing power.
Multilingual Support: Essential for applications targeting diverse linguistic audiences.
Ease of Deployment: Assess the complexity of integrating and maintaining the model within your infrastructure.
3. Vector Databases & Search
Once data is embedded into vectors, efficient storage and retrieval become paramount. Vector databases are specialized systems designed to handle high-dimensional vector data, enabling rapid similarity searches crucial for applications like semantic search and RAG.
Options:
Managed/Cloud Services:
Pinecone: A fully managed vector database optimized for real-time applications.
Zilliz Cloud: Provides cloud-native vector database services with high availability.
Vertex AI Vector Search: Google Cloud’s solution for vector similarity search.
Elasticsearch: While traditionally a text search engine, it now supports vector search functionalities.
Open-source/Self-hosted:
Milvus: Designed for scalable similarity search, supporting billions of vectors.
Weaviate: An open-source vector search engine with modular architecture.
Qdrant: Focuses on high-performance vector similarity search.
Chroma: Tailored for AI applications, offering simple APIs for vector storage and retrieval.
FAISS: Developed by Facebook, it’s a library for efficient similarity search and clustering of dense vectors.
pgvector: A PostgreSQL extension that adds vector similarity search capabilities to the database.
Considerations:
Scalability: Ensure the database can handle your data volume and query load.
Query Speed: Evaluate the latency and throughput for similarity searches.
Filtering Capabilities: Ability to filter results based on metadata or other criteria.
Metadata Storage: Support for storing additional information alongside vectors.
Hybrid Search: Combining vector and traditional keyword search for enhanced results.
Cost: Consider both operational expenses and infrastructure requirements.
Model Layer: The Brains of the Operation
At the heart of every LLM application lies the model layer, the engine that processes inputs and generates intelligent outputs. Selecting the right model and deployment strategy is crucial for performance, scalability, and cost-effectiveness.
1. Choosing Your Large Language Model (LLM)
Proprietary Models:
OpenAI (GPT-4, GPT-4.1, GPT-4o): Renowned for their advanced reasoning and multimodal capabilities. GPT-4.1 offers a one million token context window, enhancing its ability to handle extensive inputs.
Anthropic (Claude 3 Series): Designed with safety and interpretability in mind. The Claude 3 models demonstrate nuanced understanding and reduced refusal rates, making them reliable for sensitive applications.
Google (Gemini, PaLM): Gemini models are multimodal, processing text, images, audio, and more. Gemini 2.5 Pro has been noted for its competitive performance in various benchmarks.
Cohere: Offers a suite of models optimized for enterprise applications, with a focus on multilingual support and customization.
Open-Source Models:
Meta (Llama Series): Llama 3.1, with up to 405B parameters, is among the most capable openly available models, suitable for a broad range of use cases.
Mistral (Mixtral): Employs a sparse mixture-of-experts architecture, enhancing efficiency and performance.
Falcon: Available in sizes up to 180B parameters, Falcon models are optimized for performance and scalability.
Yi Series: Trained on a 3T multilingual corpus, Yi models excel in language understanding and reasoning tasks.
Considerations:
Capabilities: Assess the model’s proficiency in reasoning, creativity, and specific task performance.
Context Window: Ensure the model can handle the length of your inputs effectively.
Cost: Balance performance needs with budget constraints.
Deployment Flexibility: Determine if API access suffices or if self-hosting is preferable for your use case.
2. Model Access & Deployment
API Access:
OpenAI, Anthropic, Cohere: Provide robust APIs for seamless integration into applications.
Managed Endpoints:
AWS SageMaker, Google Vertex AI, Azure ML: Offer scalable solutions for deploying and managing models without the overhead of infrastructure maintenance.
Self-Hosting:
vLLM: An efficient inference engine compatible with the OpenAI API protocol, requiring GPUs with compute capability ≥7.0.
Text Generation Inference (TGI): Supports high-performance text generation with features like quantization and token streaming.
Considerations:
Infrastructure Requirements: Evaluate hardware needs, especially GPU capabilities, for self-hosting.
Scalability: Ensure the deployment method aligns with your application’s growth projections.
Latency: Consider the impact of deployment choices on response times.
3. Fine-Tuning Infrastructure & Platforms
Tools:
Hugging Face Transformers: Provides a comprehensive library for model training and fine-tuning.
LoRA/QLoRA: Parameter-efficient fine-tuning techniques that reduce computational requirements.
Axolotl: An open-source tool designed to simplify the fine-tuning process across various models.
OpenPipe: Facilitates continuous fine-tuning with minimal code changes, streamlining the adaptation process.
Lamini: Offers a platform for rapid and cost-effective fine-tuning, enabling deployment of smaller, specialized models.
Platforms:
Predibase, Brev.dev, RunPod, Anyscale: Provide infrastructure and tools to support the fine-tuning and deployment of LLMs, catering to various scalability and customization needs.
Considerations:
Data Privacy: Ensure that fine-tuning processes comply with data protection regulations.
Resource Allocation: Balance the computational demands of fine-tuning with available resources.
Model Performance: Monitor improvements post fine-tuning to validate the efficacy of the process.
Orchestration & Application Logic Layer: Connecting the Dots
This layer serves as the glue binding your data, models, and user interactions. It orchestrates the flow of information, ensuring seamless communication between components.
1. LLM Frameworks & SDKs
Frameworks streamline the development of LLM applications by providing tools for chaining tasks, managing prompts, and integrating external data sources.
LangChain: Offers a modular approach to building LLM workflows, supporting various integrations and memory management.
Haystack: Focuses on production-ready search pipelines, particularly for document-based question answering and information retrieval.
Semantic Kernel: Designed for enterprise applications, it supports skill-based orchestration and integrates with multiple programming languages.
When to Use:
LangChain: For complex, multi-step workflows requiring integration with various tools.
LlamaIndex: When dealing with large, private datasets needing efficient retrieval.
Haystack: For building scalable, production-grade search applications.
Semantic Kernel: In enterprise settings requiring robust skill orchestration and multi-language support.
2. Prompt Engineering & Management
Effective prompt engineering is crucial for guiding LLMs to produce desired outputs. Managing and iterating on prompts ensures consistency and performance.
PromptLayer: Provides tools for prompt versioning, testing, and analytics, facilitating collaboration between technical and non-technical teams.
Helicone: Offers observability features, allowing developers to monitor prompt performance and debug issues effectively.
PromptPerfect: Focuses on optimizing prompt quality and performance through evaluation tools and real-time feedback.
Best Practices:
Utilize version control for prompts to track changes and performance over time.
Conduct A/B testing to compare prompt effectiveness.
Collaborate across teams to refine prompts, incorporating feedback from various stakeholders.
The Operational Layer, or LLMOps, is the backbone of any large language model application. It ensures that your LLMs run smoothly, securely, and efficiently in production environments.
1. Monitoring & Observability
Effective monitoring is crucial for understanding your model’s behavior and performance. It helps in identifying issues, optimizing performance, and ensuring user satisfaction.
Key Tools:
Helicone: Provides comprehensive observability features, including cost tracking and prompt performance analysis.
LangSmith: Offers detailed tracing and debugging capabilities for LLM applications.
LangFuse: Focuses on monitoring and evaluating LLM outputs to ensure quality and reliability.
Arize: Specializes in model performance monitoring and bias detection.
WhyLabs: Provides real-time monitoring and alerting for data and model quality.
OpenTelemetry & Grafana: Enable standardized tracing and visualization of LLM metrics.
Prometheus & Datadog: Offer robust infrastructure monitoring and alerting capabilities.
2. Evaluation & Testing
Regular evaluation ensures that your LLMs produce accurate, relevant, and safe outputs. It involves both automated metrics and human-in-the-loop assessments.
Key Tools:
DeepEval: Offers over 14 evaluation metrics, including summarization, hallucination detection, and bias assessment.
TruLens: Provides tools for evaluating LLM outputs based on trustworthiness and relevance.
Giskard: Incorporates human-in-the-loop evaluation to validate model outputs.
Ragas: Focuses on evaluating retrieval-augmented generation (RAG) systems.
Best Practices:
Implement A/B testing to compare different model versions.
Use human reviewers to assess output quality and relevance.
Regularly update evaluation metrics to align with evolving standards.
3. Deployment & Infrastructure
Efficient deployment ensures that your LLMs are accessible, scalable, and maintainable. It involves containerization, orchestration, and continuous integration/continuous deployment (CI/CD) pipelines.
Key Components:
Containerization: Use Docker to package your applications for consistent deployment.
Orchestration: Employ Kubernetes for managing containerized applications at scale.
CI/CD Pipelines: Implement GitHub Actions, Jenkins, or GitLab CI for automated testing and deployment.
Serverless Options: Leverage AWS Lambda or Google Cloud Functions for event-driven execution.
API Gateways: Utilize Cloudflare AI Gateway, Portkey, or Apigee for routing, rate limiting, and security.
4. Security & Governance
Securing your LLM applications is paramount to protect sensitive data and maintain user trust. It involves implementing safeguards against prompt injection, data leaks, and unauthorized access.
Key Strategies:
Prompt Injection Prevention: Monitor and sanitize inputs to prevent malicious prompts.
Data Privacy: Use tools like Microsoft Presidio for PII redaction and ensure compliance with regulations like GDPR and HIPAA.
Access Control: Implement role-based access control (RBAC) to restrict model usage.
Monitoring: Continuously monitor API calls and model outputs for anomalies.
5. Cost Management
Managing costs is essential to ensure the sustainability of your LLM applications. It involves tracking usage, optimizing resources, and selecting cost-effective solutions.
Key Practices:
Usage Tracking: Monitor token usage and API calls to identify cost drivers.
Prompt Optimization: Refine prompts to reduce unnecessary token consumption.
Model Selection: Choose models that balance performance with cost-effectiveness.
Infrastructure Efficiency: Optimize deployment environments to minimize resource wastage.
What to Consider Before You Build Your LLM Stack
1. Use Case Specifics
Not all LLM applications are created equal. The goal of your app should shape everything, from architecture to tooling.
RAG (Retrieval-Augmented Generation) is ideal for Q&A systems, customer support bots, or enterprise search, where you need fresh, query-specific answers based on external documents.
Fine-tuning works better for style-sensitive tasks like summarization, email generation, or legal writing, where tone, format, and consistency matter more than freshness.
Ask yourself that Will your app benefit more from real-time document retrieval or specialized language understanding?
2. Data Availability and Sensitivity
Your data fuels your model. The type, quality, and sensitivity of that data directly impacts your stack choices.
If you’re using proprietary or sensitive data, you may need self-hosted models and vector databases to ensure compliance.
If your data is public or generic, managed services (e.g., OpenAI API + Pinecone) may be fine.
Secure first, build second. Data privacy and governance rules (like GDPR or HIPAA) must inform your design.
3. Scalability and Performance Requirements
LLM workloads can grow quickly. You’ll need a stack that meets your current performance needs, but can also scale without breaking the bank.
Consider latency if you’re building real-time apps (e.g., chatbots, live search).
Measure throughput if you expect high user volume or batch processing.
Choose infrastructure (e.g., serverless, autoscaling, GPU-optimized deployments) that aligns with these expectations.
Use observability tools early to identify bottlenecks before they scale with your users.
4. Budget and Cost Implications
Costs in LLM applications can spiral quickly, especially with high token usage or GPU-intensive inference.
API usage (OpenAI, Anthropic) can scale linearly with usage, great for prototyping, expensive at scale.
Self-hosting offers better control over costs but requires upfront infra and engineering.
Tools like Helicone and PromptLayer help track and optimize usage.
Choose wisely: Don’t just think about today, model your 3x and 10x user growth scenarios too.
5. Team Skills and Expertise
Your tech stack should match the skills of your team, not fight against them.
Have strong ML engineers? Fine-tuning and self-hosting might be doable.
Leaning on generalist developers? Go with API-first services and frameworks like LangChain or LlamaIndex.
No DevOps? Avoid building from scratch. Use managed solutions wherever possible.
6. Build vs. Buy vs. Open Source
There’s no one-size-fits-all answer here. The real question is: Where do you want to invest your time and talent?
Build: Custom components give you control, but require long-term maintenance.
Buy: SaaS tools get you to market faster, but come with lock-in and licensing fees.
OSS: Open-source tools offer flexibility, but you’ll need in-house expertise.
Use OSS or APIs for what’s been solved. Build only what differentiates you.
7. Vendor Lock-In vs. Flexibility
Lock-in can creep in fast, through APIs, formats, or infrastructure decisions.
Favor open standards (like OpenAI-compatible APIs, pgvector) where possible.
Choose tools that let you switch out models or run locally if needed.
Read the fine print, especially with closed APIs that limit usage, control, or portability.
8. The Evolving Landscape
The LLM ecosystem moves fast. What’s best today may be outdated in six months.
Stay plugged in through newsletters, GitHub repos, and vendor changelogs.
Design your stack with modularity in mind, so you can swap in new tools without breaking your app.
Be ready to test new releases (like Llama 3 or GPT-4.1) without major rework.
Staying updated with evolving AI trends like multimodal LLMs, smaller task-specific models, or AI agents is key to making the right architectural decisions. Your stack should be modular enough to pivot with these innovations.
Example of LLM Tech Stacks for Common Use Cases
Choosing the right tools is easier when you see how they come together in real-world scenarios. Below are two common LLM application patterns, each with a sample stack that’s reliable, modular, and production-ready.
1. RAG-Based Q&A Bot
This setup is ideal for building a smart assistant that answers questions using your own data. Think internal support tools, document search engines, or customer-facing bots.
Sample Stack:
Data Ingestion → Unstructured.io
– Parses PDFs, DOCs, HTML, etc. into clean text chunks.
Embeddings → OpenAI (text-embedding-3-small)
– Converts text into vectors optimized for semantic search.
More predictable and stylized outputs than generic APIs.
3. Autonomous AI Agent for Task Automation
This stack powers an AI agent capable of taking actions based on goals, like scheduling meetings, replying to emails, or managing workflows. If you’re exploring advanced assistants or automation tools, working with an experienced AI agent development company can accelerate your journey from prototype to production.
Sample Stack:
Task Input → Natural language command
Orchestration → LangChain Agent with Toolkits
Knowledge Access → RAG using Weaviate + OpenAI Embeddings
Why it works: It gives your app real-world agency, letting users interact with complex systems through a single natural language interface.
Build Your Ideal LLM Application with Prismetric’s Expertise
Building a reliable, scalable LLM application takes more than picking the right tools, it takes experience. At Prismetric, we help teams go from idea to impact with tailored AI solutions that work in the real world.
Whether you’re looking to create a RAG-powered knowledge assistant, deploy a custom-trained model, or launch a production-ready AI chatbot, our experts can help you build faster, smarter, and more securely.
Why Partner with Prismetric for building LLM Application?
Full-Stack Support: From data pipelines to deployment, we design and implement complete LLM stacks aligned with your business goals.
Custom Fine-Tuning: Our LLM fine-tuning services help you adapt leading models like LLaMA 2 or GPT-J to your unique voice, use case, or dataset.
Conversational AI Done Right: Need a virtual assistant or internal knowledge bot? Our AI chatbot development team builds intuitive, human-like interactions with advanced natural language understanding.
Scalable Architecture: Whether you choose OpenAI APIs or prefer self-hosted models, we ensure your infrastructure scales effortlessly.
Security First: We implement strong data governance, privacy protections, and access controls tailored to your compliance needs.
Your Trusted AI Development Company
Prismetric isn’t just another AI development company. We’re a strategic partner for startups, enterprises, and product teams that want to lead, not just follow, in the age of AI.
Let us help you:
Choose the right model and deployment strategy
Build reliable, production-grade LLM applications
Optimize performance, reduce costs, and ensure long-term maintainability
Ready to build your next-gen LLM product? Talk to our experts today and turn your AI vision into a working reality.
Conclusion
Building LLM applications means making smart, connected choices about models, data, and tools. Whether you go with RAG or fine-tuning, your approach shapes everything from performance to scalability.
The best stacks don’t start perfect. You build, test, and improve. Start small, ship fast, and learn as you go. Each layer from data to deployment gets better with iteration.
This space moves fast. New tools and models keep raising the bar. Stay flexible, keep experimenting, and let your stack evolve with your goals.
Hardik Shah
As the tech-savvy Project Manager at Prismetric, his admiration for app technology is boundless though!He writes widely researched articles about the AI development, app development methodologies, codes, technical project management skills, app trends, and technical events. Inventive mobile applications and Android app trends that inspire the maximum app users magnetize him deeply to offer his readers some remarkable articles.
Get thoughtful updates on what’s new in technology and innovation
Streamline your operations and grow your business by getting the best application built


 AI Voice Agent Development
AI Voice Agent Development Enterprise AI Chatbot
Enterprise AI Chatbot